![[Tips] Amazon Athena 6億レコードのサンプルデータ「SSB」を準備する](https://images.ctfassets.net/ct0aopd36mqt/wp-thumbnail-764c44f07bcd41184fe62a432ae120ab/512a4cdcd05a0ed3ddea950fdf619fa0/amazon-athena?w=3840&fm=webp)
[Tips] Amazon Athena 6億レコードのサンプルデータ「SSB」を準備する
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
AWS事業本部コンサルティング部の石川です。これまで数多くの技術検証ブログを書いてきましたが、今日は、その中でよく使うサンプルデータ「SSB」があります。中でもlineorderテーブルは6億レコードあり、それを囲むスタースキーマ構成のデータは検証には欠かせないものです。今日は、そのAmazon Athenaでサンプルデータ「SSB」を使えるようにする方法をご紹介します。
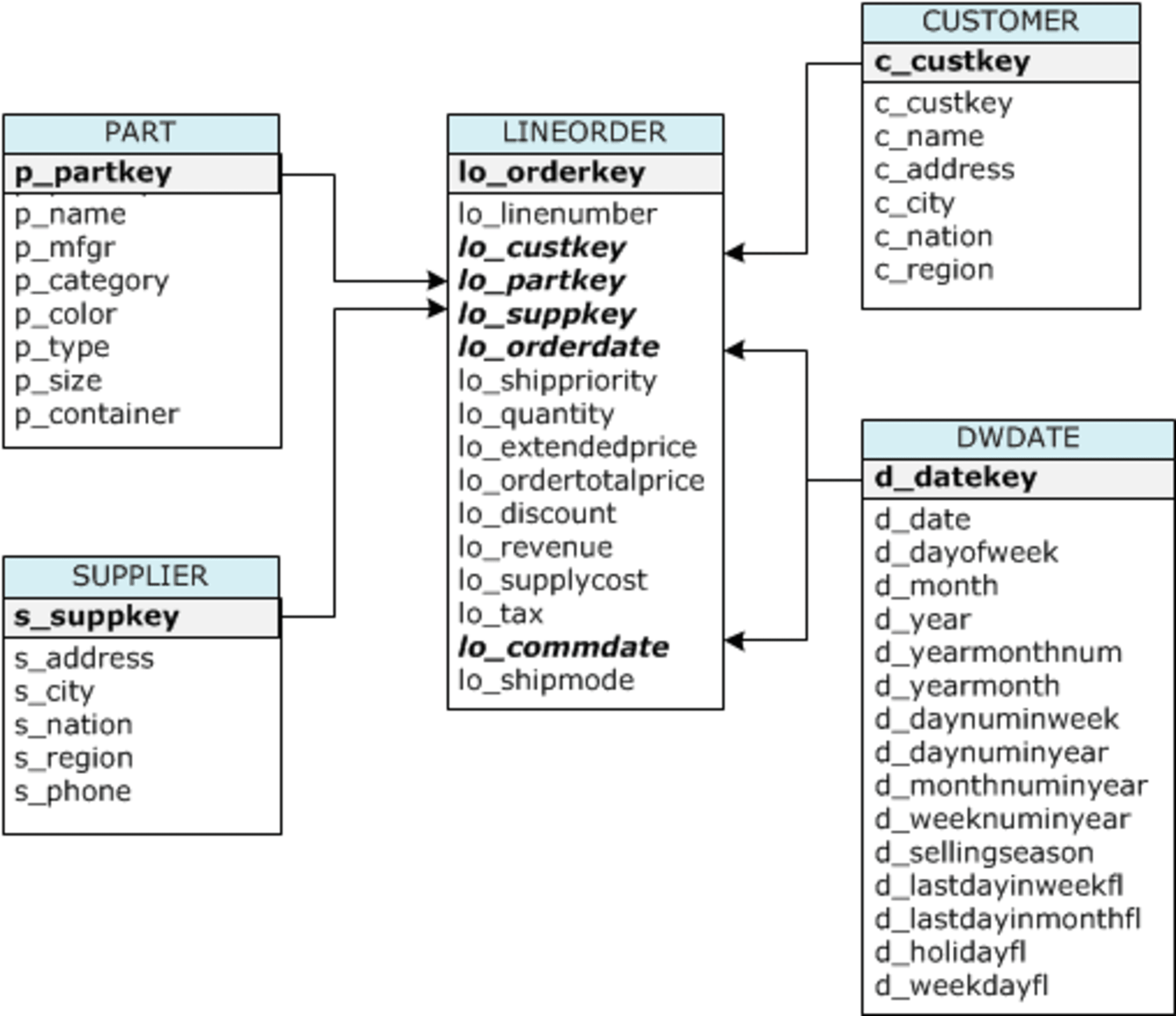
SSB サンプルデータとは?
SSB (Star Schema Benchmark) サンプルデータは、データウェアハウスのパフォーマンステストや機能デモンストレーションに広く使用されるベンチマークデータセットです。以下にSSBサンプルデータの主な特徴をまとめます。
データ構造
- スタースキーマモデルに基づいています。
- 主に5つのテーブルで構成されています。
- LINEORDER (ファクトテーブル)
- CUSTOMER (ディメンションテーブル)
- PART (ディメンションテーブル)
- SUPPLIER (ディメンションテーブル)
- DWDATE (ディメンションテーブル)
ER図
データ量
- LINEORDERテーブルは約6億行、約30GB(圧縮)のデータを含む大規模なファクトテーブルです。
- その他のディメンションテーブルも数百万行のデータを含んでいます。
用途
- データウェアハウスのパフォーマンステスト
- 複数テーブルのJOINクエリのパフォーマンス評価
- データベース製品やクラウドサービスの機能デモンストレーション
- ETLおよびELTプロセスの設計パターンの検証
特徴
- TPC-Hをベースに簡略化されたスタースキーマデータを提供しています。
- Amazon RedshiftやOracle Autonomous Databaseなど、様々なデータベース製品でサポートされています。
- データは通常、圧縮形式(例:GZIP)で提供され、S3バケットなどのクラウドストレージに保存されています。
- 分析系クエリの実行やデータロード、アンロードなどの操作を試すのに適しています。
データのアクセス方法
AWSのオレゴンリージョン(us-west-2)のS3バケット( s3://awssampledbuswest2/ssbgz/ )で公開されており、認証されたユーザーがアクセスできます。以前は各リージョンにあったのですが、現在はオレゴンのみで提供されているようです。
実際に利用する場合は、Amazon Athenaと同じリージョンのS3バケットにコピーして使うことになります。以下の例では、オレゴンリージョン(us-west-2)のssbgzフォルダのデータを東京リージョン(ap-northeast-1)にAmazon Athenaが利用できるレイアウトでコピーするコマンドです。
aws s3 cp s3://awssampledbuswest2/ssbgz/customer0002_part_00.gz s3://<your_bucket>/ssbgz/customer/ --source-region us-west-2 --region ap-northeast-1 --copy-props none
aws s3 cp s3://awssampledbuswest2/ssbgz/dwdate.tbl.gz s3://<your_bucket>/ssbgz/dwdate/ --source-region us-west-2 --region ap-northeast-1 --copy-props none
aws s3 cp s3://awssampledbuswest2/ssbgz/lineorder0000_part_00.gz s3://<your_bucket>/ssbgz/lineorder/ --source-region us-west-2 --region ap-northeast-1 --copy-props none
aws s3 cp s3://awssampledbuswest2/ssbgz/lineorder0001_part_00.gz s3://<your_bucket>/ssbgz/lineorder/ --source-region us-west-2 --region ap-northeast-1 --copy-props none
aws s3 cp s3://awssampledbuswest2/ssbgz/lineorder0002_part_00.gz s3://<your_bucket>/ssbgz/lineorder/ --source-region us-west-2 --region ap-northeast-1 --copy-props none
aws s3 cp s3://awssampledbuswest2/ssbgz/lineorder0003_part_00.gz s3://<your_bucket>/ssbgz/lineorder/ --source-region us-west-2 --region ap-northeast-1 --copy-props none
aws s3 cp s3://awssampledbuswest2/ssbgz/lineorder0004_part_00.gz s3://<your_bucket>/ssbgz/lineorder/ --source-region us-west-2 --region ap-northeast-1 --copy-props none
aws s3 cp s3://awssampledbuswest2/ssbgz/lineorder0005_part_00.gz s3://<your_bucket>/ssbgz/lineorder/ --source-region us-west-2 --region ap-northeast-1 --copy-props none
aws s3 cp s3://awssampledbuswest2/ssbgz/lineorder0006_part_00.gz s3://<your_bucket>/ssbgz/lineorder/ --source-region us-west-2 --region ap-northeast-1 --copy-props none
aws s3 cp s3://awssampledbuswest2/ssbgz/lineorder0007_part_00.gz s3://<your_bucket>/ssbgz/lineorder/ --source-region us-west-2 --region ap-northeast-1 --copy-props none
aws s3 cp s3://awssampledbuswest2/ssbgz/part0000_part_00.gz s3://<your_bucket>/ssbgz/part/ --source-region us-west-2 --region ap-northeast-1 --copy-props none
aws s3 cp s3://awssampledbuswest2/ssbgz/part0001_part_00.gz s3://<your_bucket>/ssbgz/part/ --source-region us-west-2 --region ap-northeast-1 --copy-props none
aws s3 cp s3://awssampledbuswest2/ssbgz/part0002_part_00.gz s3://<your_bucket>/ssbgz/part/ --source-region us-west-2 --region ap-northeast-1 --copy-props none
aws s3 cp s3://awssampledbuswest2/ssbgz/part0003_part_00.gz s3://<your_bucket>/ssbgz/part/ --source-region us-west-2 --region ap-northeast-1 --copy-props none
aws s3 cp s3://awssampledbuswest2/ssbgz/supplier.tbl_0000_part_00.gz s3://<your_bucket>/ssbgz/supplier/ --source-region us-west-2 --region ap-northeast-1 --copy-props none
以下のような構成でファイルが配置されます。
% aws s3 ls s3://<your_bucket>/ssbgz/ --recursive --profile ishikawa
2024-11-10 22:52:13 105338147 ssbgz/customer/customer0002_part_00.gz
2024-11-10 22:52:19 25239 ssbgz/dwdate/dwdate.tbl.gz
2024-11-10 22:52:20 3371631839 ssbgz/lineorder/lineorder0000_part_00.gz
2024-11-10 22:54:10 3371582385 ssbgz/lineorder/lineorder0001_part_00.gz
2024-11-10 22:55:39 3371613250 ssbgz/lineorder/lineorder0002_part_00.gz
2024-11-10 22:57:08 3371648328 ssbgz/lineorder/lineorder0003_part_00.gz
2024-11-10 22:58:36 3371300610 ssbgz/lineorder/lineorder0004_part_00.gz
2024-11-10 23:00:05 3371302892 ssbgz/lineorder/lineorder0005_part_00.gz
2024-11-10 23:02:06 3371731806 ssbgz/lineorder/lineorder0006_part_00.gz
2024-11-10 23:03:36 3371692315 ssbgz/lineorder/lineorder0007_part_00.gz
2024-11-10 23:05:27 8682594 ssbgz/part/part0000_part_00.gz
2024-11-10 23:05:31 8686135 ssbgz/part/part0001_part_00.gz
2024-11-10 23:05:34 8674736 ssbgz/part/part0002_part_00.gz
2024-11-10 23:05:37 8680668 ssbgz/part/part0003_part_00.gz
2024-11-10 23:05:40 34110217 ssbgz/supplier/supplier.tbl_0000_part_00.gz
データベースの作成
Amazon Athenaのクエリエディタで、このサンプルデータ用のデータベースを作成します。
CREATE DATABSE ssb;
テーブルの作成
Amazon Athenaのクエリエディタで、以下の5つのテーブルを順に作成します。さきほど作成したデータベースを選択することを忘れないでください。
LINEORDER
-- 600037902 records
CREATE EXTERNAL TABLE lineorder
(
lo_orderkey INT,
lo_linenumber INT,
lo_custkey INT,
lo_partkey INT,
lo_suppkey INT,
lo_orderdate INT,
lo_orderpriority VARCHAR(15),
lo_shippriority VARCHAR(1),
lo_quantity INT,
lo_extendedprice INT,
lo_ordertotalprice INT,
lo_discount INT,
lo_revenue INT,
lo_supplycost INT,
lo_tax INT,
lo_commitdate INT,
lo_shipmode VARCHAR(10))
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '|'
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
's3://<your_bucket>/ssbgz/lineorder/'
TBLPROPERTIES (
'CrawlerSchemaDeserializerVersion'='1.0',
'CrawlerSchemaSerializerVersion'='1.0',
'UPDATED_BY_CRAWLER'='lineorder',
'areColumnsQuoted'='false',
'classification'='csv',
'columnsOrdered'='true',
'compressionType'='gzip',
'delimiter'='|',
'typeOfData'='file')
CUSTOMER
-- 3000000 records
CREATE EXTERNAL TABLE `customer`(
c_custkey INT,
c_name VARCHAR(25),
c_address VARCHAR(25),
c_city VARCHAR(10),
c_nation VARCHAR(15),
c_region VARCHAR(12),
c_phone VARCHAR(15),
c_mktsegment VARCHAR(10))
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '|'
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
's3://<your_bucket>/ssbgz/customer/'
TBLPROPERTIES (
'CrawlerSchemaDeserializerVersion'='1.0',
'CrawlerSchemaSerializerVersion'='1.0',
'UPDATED_BY_CRAWLER'='customer',
'areColumnsQuoted'='false',
'classification'='csv',
'columnsOrdered'='true',
'compressionType'='gzip',
'delimiter'='|',
'typeOfData'='file')
PART
-- 350024 records
CREATE EXTERNAL TABLE part
(
p_partkey INT,
p_name VARCHAR(22) ,
p_mfgr VARCHAR(6),
p_category VARCHAR(7) ,
p_brand1 VARCHAR(9) ,
p_color VARCHAR(11) ,
p_type VARCHAR(25) ,
p_size INT,
p_container VARCHAR(10))
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '|'
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
's3://<your_bucket>/ssbgz/part/'
TBLPROPERTIES (
'CrawlerSchemaDeserializerVersion'='1.0',
'CrawlerSchemaSerializerVersion'='1.0',
'UPDATED_BY_CRAWLER'='part',
'areColumnsQuoted'='false',
'classification'='csv',
'columnsOrdered'='true',
'compressionType'='gzip',
'delimiter'='|',
'typeOfData'='file')
SUPPLIER
-- 1000000 records
CREATE EXTERNAL TABLE supplier
(
s_suppkey INT,
s_name VARCHAR(25),
s_address VARCHAR(25),
s_city VARCHAR(10),
s_nation VARCHAR(15),
s_region VARCHAR(12),
s_phone VARCHAR(15))
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '|'
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
's3://<your_bucket>/ssbgz/supplier/'
TBLPROPERTIES (
'CrawlerSchemaDeserializerVersion'='1.0',
'CrawlerSchemaSerializerVersion'='1.0',
'UPDATED_BY_CRAWLER'='supplier',
'areColumnsQuoted'='false',
'classification'='csv',
'columnsOrdered'='true',
'compressionType'='gzip',
'delimiter'='|',
'typeOfData'='file')
DWDATE
-- 2556 records
CREATE EXTERNAL TABLE dwdate
(
d_datekey INT ,
d_date VARCHAR(19),
d_dayofweek VARCHAR(10),
d_month VARCHAR(10),
d_year INT,
d_yearmonthnum INT,
d_yearmonth VARCHAR(8),
d_daynuminweek INT,
d_daynuminmonth INT,
d_daynuminyear INT,
d_monthnuminyear INT,
d_weeknuminyear INT,
d_sellingseason VARCHAR(13),
d_lastdayinweekfl VARCHAR(1),
d_lastdayinmonthfl VARCHAR(1),
d_holidayfl VARCHAR(1),
d_weekdayfl VARCHAR(1))
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '|'
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
's3://<your_bucket>/ssbgz/dwdate/'
TBLPROPERTIES (
'CrawlerSchemaDeserializerVersion'='1.0',
'CrawlerSchemaSerializerVersion'='1.0',
'UPDATED_BY_CRAWLER'='dwdate',
'areColumnsQuoted'='false',
'classification'='csv',
'columnsOrdered'='true',
'compressionType'='gzip',
'delimiter'='|',
'typeOfData'='file')
最後に
SSBサンプルデータは、データウェアハウスやビッグデータ分析の分野で、製品やサービスの性能評価やデモンストレーションに広く活用されている標準的なデータセットです。今回利用したデータファイルは、Amazon Redshift用のデータをAmazon Athenaに流用しました。私はこのデータをそのままではなく、更に様々なデータ型やフォーマットのデータを作成して利用しています。
実際のビジネスシナリオを模した現実的なデータ構造と十分な量のデータを提供しているため、様々なデータ処理や分析タスクの検証に適しています。
参考文献










